
Hallo,
ich schreibe gerade meine Masterarbeit und versuche ein wissenschaftliches Paper "nach zu bauen". Es geht darum, welche Faktoren (Bruttoinlandsprodukt, Auslandsverschuldung, Inflation, etc.) einen Einfluss auf das Rating eines jeweiligen Landes haben.
Die Ratings sind von den 3 großen Ratingagenturen und gehen von AAA (=sehr gut) bis C bzw. D (=sehr schlecht). Die Ratings sind somit ordinal und stellen meine abhängige Variable dar, die getrennt auf den Einfluss der Faktoren analysiert werden sollen.
Die erklärenden Variablen liegen in %, wie z.B. die Inflation oder in Absolutbeträgen, wie z.B. das Bruttoinlandsprodukt vor. Die Variablen sind somit Skalen.
Laut meiner Aufgabenstellung und des nach zu bauenden Papers soll die Analyse mit Hilfe des Ordered Probit Verfahren gemacht werden.
Ich benutze SPSS Version 20. Aktuell gehe ich wie folgt vor. Analysieren--> Regression--> Ordinal (Abhängige und Faktoren (d.h. unabhängige Variablen einfügen); im Menüpunkt Option die Link-Funktion auf Probit ändern)--> Berechnung durchführen.
Als Ausgabe erscheint zu erst die Tabelle der Zusammenfassung der Fallverarbeitung.
Als zweites erscheint die Information zur Modellanpassung (Es liegt eine Signifikanz von 0,000 vor. Dies ist schon mal positiv!)
Die Dritte Tabelle ist die Anpassungsgüte und hat eine Signifikanz von 1,0--> Spricht für die Anpassungsgüte des Modells.
Als viertes erfolgt die Ausgabe der Pseudo R-Quadrate. Dies ist der erste Punkt, der mich verwirrt. Die Werte von Cox und Snell liegen meist bei 0,9 und die Werte von Nagelkerke und McFadden liegen 1,0. Dies bedeutet doch, dass meine ausgewählten Variablen (BIP, Inflation etc.) zu 100% die Änderung des Ratings erklären? Ist das Richtig? Im nachzubauenden Paper sind sie deutlich geringer...
Wer bis hierher schon gelesen hat--> Vielen Dank...ich hab nur noch eine Frage;)
Die letzte Sache, die mich verwirrt ist die Ausgabe der Werte. In meinem "nach zu bauenden" Paper liegen die Regressionskoeffizienten für die einzelnen Variablen gesammelt vor, d.h. für die einzelne Variable z.B. Inflation liegt ein einzelner Wert vor.
Bei der Ausgabe meiner Werte ist es jedoch so, dass für jede Ausprägung meiner unabhängigen Variable ein Schätzer vorliegt (D.h. die Inflationsrate von 3,1% hat einen Schätzer, die Inflationsrate von 3,6% hat einen Wert usw.). Was mache ich falsch bzw. wie ist es möglich die einzelnen Regressionskoeffizienten zusammen zu fassen?
Und nochmals vielen Dank wer bis zum Ende gelesen hat.....
Ordered Probit/ Regression
5 Beiträge
• Seite 1 von 1
Ordered Probit/ Regression
![]() von lecoewf » Fr 1. Feb 2013, 16:02
von lecoewf » Fr 1. Feb 2013, 16:02
- lecoewf
- Beiträge: 7
- Registriert: Fr 25. Jan 2013, 19:02
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Ordered Probit/ Regression
![]() von aziz » Fr 1. Feb 2013, 18:01
von aziz » Fr 1. Feb 2013, 18:01
Hallo,
Du benutzt nicht die origninalen Daten aus dem Paper?
Die Durchführung hört sich ansich in Ordnung an. Nur, habe ich dich richtig verstanden? Du hast deine unabhängigen Variablen als Faktoren eingefügt? Das würd erklären, warum du für jede Merkmalsausprägung einen Koeffizienten besitzt. Für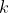 Merkmalsausprägungen werden
Merkmalsausprägungen werden 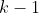 Dummyvariablen in das Modell genommen. Wenn dem so ist, so solltest du deine intervallsalierten Variablen in dem Feld Kovariate modellieren.
Dummyvariablen in das Modell genommen. Wenn dem so ist, so solltest du deine intervallsalierten Variablen in dem Feld Kovariate modellieren.
Gruß
a.
lecoewf hat geschrieben:Als viertes erfolgt die Ausgabe der Pseudo R-Quadrate. Dies ist der erste Punkt, der mich verwirrt. Die Werte von Cox und Snell liegen meist bei 0,9 und die Werte von Nagelkerke und McFadden liegen 1,0. Dies bedeutet doch, dass meine ausgewählten Variablen (BIP, Inflation etc.) zu 100% die Änderung des Ratings erklären? Ist das Richtig? Im nachzubauenden Paper sind sie deutlich geringer...
Du benutzt nicht die origninalen Daten aus dem Paper?
lecoewf hat geschrieben:Ich benutze SPSS Version 20. Aktuell gehe ich wie folgt vor. Analysieren--> Regression--> Ordinal (Abhängige und Faktoren (d.h. unabhängige Variablen einfügen); im Menüpunkt Option die Link-Funktion auf Probit ändern)--> Berechnung durchführen.
...
Bei der Ausgabe meiner Werte ist es jedoch so, dass für jede Ausprägung meiner unabhängigen Variable ein Schätzer vorliegt (D.h. die Inflationsrate von 3,1% hat einen Schätzer, die Inflationsrate von 3,6% hat einen Wert usw.). Was mache ich falsch bzw. wie ist es möglich die einzelnen Regressionskoeffizienten zusammen zu fassen?
Die Durchführung hört sich ansich in Ordnung an. Nur, habe ich dich richtig verstanden? Du hast deine unabhängigen Variablen als Faktoren eingefügt? Das würd erklären, warum du für jede Merkmalsausprägung einen Koeffizienten besitzt. Für
Gruß
a.
- aziz
- Beiträge: 34
- Registriert: Di 29. Jan 2013, 17:28
- Danke gegeben: 0
- Danke bekommen: 3 mal in 3 Posts
Re: Ordered Probit/ Regression
![]() von lecoewf » Sa 2. Feb 2013, 17:48
von lecoewf » Sa 2. Feb 2013, 17:48
Hallo aziz,
ich möchte mich erstmal für deine schnelle Antwort bedanken. Ich habe es versucht umzusetzen, jedoch existieren noch ein "paar" Fragen, die ich noch nicht zu meiner Zufriedenheit habe beantworten können.
Zu erst einmal jedoch zu deine Frage:
Nein, ich benutze nicht die Originaldaten. Im ursprünglichen Paper wird die Untersuchung nur für die Ratingagentur Moody´s durchgeführt. Ich hingegen untersuche mögliche Variablen für die drei bekanntesten Ratingagenturen Moody´s, Standard & Poor´s und Fitch. Des Weiteren betrachte ich die Ratings von einer anderen Ländergruppe als im ursprünglichen Paper und zusätzlich nehme ich die Ratings aus einer anderen zeitliche Periode als im ursprünglichen Paper. Im Endeffekt "klaue" ich nur die Idee zu untersuchen, welche Faktoren eine Rolle für das Rating spielen.
Ich hoffe, dass hilft dir beim Verständnis meiner Untersuchung.
Wie gesagt, ich habe nur deinen Vorschlag die erklärenden Variablen als Kovariate einzusetzen umgesetzt und erhalte nun für jede Variablen einen einzelnen Regressionskoeffizient. Dies entspricht meinem Wunsch, wie die Ergebnisse dargestellt werden sollen. Was mich jedoch verwirrt ist, ob es wirklich Kovariate sind? Denn ich dachte immer, dass Kovariate eine Variable ist, von der vermutet wird oder bekannt ist, daß sie als Drittvariable den Zusammenhang zwischen anderen Variablen beeinflußt.
Ist diese Definition meinerseits korrekt? Und stimmt dass denn für meine erklärenden Variablen?
Vielen Dank erstmal für alle, die mir an dieser Stelle nochmal weiterhelfen können!!
Beim umsetzen des Vorschlags von aziz sind mir jedoch ein paar weitere kleine Fragen gekommen. Ich möchte mich schonmal für jede Antwort bedanken, da ich für jede Antwort/ Verweis/ Link oder ähnliches dankbar bin, denn mein SPSS-Buch lässt mich bei den folgenden Fragen leider im Stich
1. Frage: Welches ist das passende Pseudo R-Quadrat bei meiner Fragestellung (Cox und Snell, Nagelkerke oder McFadden)?
2. Frage: In dem von mir nachgebauten Paper ist es so, dass es für jede Ordered Probit Regression einen Konstanten Term gibt. Wo steht der bei der Datenausgabe?
Ich habe nämlich herausgefungen, dass es zum Beispiel so ist, dass bei STATA dieser Wert nicht explizit ausgegeben wird. Ist dies auch bei SPSS so? Wie bekomme ich diesen Wert?
3. Frage: Ich habe die erklärende Variable "Staatsausfall seit 1945". Diese Variable nimmt den Wert 1=Staatsausfall oder 0=kein Staatsausfall seit 1945. Es handelt sich also um eine Dummy-Variable bzw. nominale Variable. Meine Frage ist, wie ich diese Variable als möglichen Regressor in der Analyse einbaue. Tue ich dies als Faktor oder als Kovariate? Denn mein schlaues SPSS-Buch sagt, dass in dem Feld Kovariate nur intervallskalierte Variablen stehen dürfen. Wie füge ich nun also diese Variable ein?
Letzte Frage: Da ich wie gesagt ein Paper "nachbaue" habe ich geguckt, wie die Ergebnisse des Papers sind um zu überprüfen, ob meine Werte in die richtige Richtung laufen. Beim "studieren" der Ergebnisse des Papers ist mir im Vergleich zu meinen Ergebnissen etwas aufgefallen was mich leicht irritiert. In dem Paper ist es so, dass erklärende Variable, die in einer ordered probit Regression einmal signifikant sind auch in jeder anderen Konstellation der erklärenden Variablen signifikant sind. Das heisst zum Beispiel, dass in der ersten Regression mit den erklärenden Variablen Bruttoinlandsprodukt, Inflationsrate und Staatsverschuldung die Variablen Bruttoinlandsprodukt und Staatsverschuldung signifikant sind. In meiner zweiten Regression mit den erklärenden Variablen Bruttoinlandsprodukt, Inflationsrate,Staatsverschuldung und zusätzlich Pro-Kopf-Einkommen sind auf einmal die signifikanten Variablen nur noch das Bruttoinlandsprodukt und das Pro-Kopf-Einkommen. Kann dies sein?
Ist es also möglich dass ein erklärende Variable in der einen Regression signifikant ist und in einer anderen Regression mit anderen erklärenden Variablen nicht mehr?
Vielen vielen Dank an Alle, die bis hierhin gelesen haben und eine möglich Antwort auf eine der Fragen haben. Dies würde mir bei meiner Masterarbeit sehr helfen...
ich möchte mich erstmal für deine schnelle Antwort bedanken. Ich habe es versucht umzusetzen, jedoch existieren noch ein "paar" Fragen, die ich noch nicht zu meiner Zufriedenheit habe beantworten können.
Zu erst einmal jedoch zu deine Frage:
Du benutzt nicht die origninalen Daten aus dem Paper?
Nein, ich benutze nicht die Originaldaten. Im ursprünglichen Paper wird die Untersuchung nur für die Ratingagentur Moody´s durchgeführt. Ich hingegen untersuche mögliche Variablen für die drei bekanntesten Ratingagenturen Moody´s, Standard & Poor´s und Fitch. Des Weiteren betrachte ich die Ratings von einer anderen Ländergruppe als im ursprünglichen Paper und zusätzlich nehme ich die Ratings aus einer anderen zeitliche Periode als im ursprünglichen Paper. Im Endeffekt "klaue" ich nur die Idee zu untersuchen, welche Faktoren eine Rolle für das Rating spielen.
Ich hoffe, dass hilft dir beim Verständnis meiner Untersuchung.
Wie gesagt, ich habe nur deinen Vorschlag die erklärenden Variablen als Kovariate einzusetzen umgesetzt und erhalte nun für jede Variablen einen einzelnen Regressionskoeffizient. Dies entspricht meinem Wunsch, wie die Ergebnisse dargestellt werden sollen. Was mich jedoch verwirrt ist, ob es wirklich Kovariate sind? Denn ich dachte immer, dass Kovariate eine Variable ist, von der vermutet wird oder bekannt ist, daß sie als Drittvariable den Zusammenhang zwischen anderen Variablen beeinflußt.
Ist diese Definition meinerseits korrekt? Und stimmt dass denn für meine erklärenden Variablen?
Vielen Dank erstmal für alle, die mir an dieser Stelle nochmal weiterhelfen können!!
Beim umsetzen des Vorschlags von aziz sind mir jedoch ein paar weitere kleine Fragen gekommen. Ich möchte mich schonmal für jede Antwort bedanken, da ich für jede Antwort/ Verweis/ Link oder ähnliches dankbar bin, denn mein SPSS-Buch lässt mich bei den folgenden Fragen leider im Stich
1. Frage: Welches ist das passende Pseudo R-Quadrat bei meiner Fragestellung (Cox und Snell, Nagelkerke oder McFadden)?
2. Frage: In dem von mir nachgebauten Paper ist es so, dass es für jede Ordered Probit Regression einen Konstanten Term gibt. Wo steht der bei der Datenausgabe?
Ich habe nämlich herausgefungen, dass es zum Beispiel so ist, dass bei STATA dieser Wert nicht explizit ausgegeben wird. Ist dies auch bei SPSS so? Wie bekomme ich diesen Wert?
3. Frage: Ich habe die erklärende Variable "Staatsausfall seit 1945". Diese Variable nimmt den Wert 1=Staatsausfall oder 0=kein Staatsausfall seit 1945. Es handelt sich also um eine Dummy-Variable bzw. nominale Variable. Meine Frage ist, wie ich diese Variable als möglichen Regressor in der Analyse einbaue. Tue ich dies als Faktor oder als Kovariate? Denn mein schlaues SPSS-Buch sagt, dass in dem Feld Kovariate nur intervallskalierte Variablen stehen dürfen. Wie füge ich nun also diese Variable ein?
Letzte Frage: Da ich wie gesagt ein Paper "nachbaue" habe ich geguckt, wie die Ergebnisse des Papers sind um zu überprüfen, ob meine Werte in die richtige Richtung laufen. Beim "studieren" der Ergebnisse des Papers ist mir im Vergleich zu meinen Ergebnissen etwas aufgefallen was mich leicht irritiert. In dem Paper ist es so, dass erklärende Variable, die in einer ordered probit Regression einmal signifikant sind auch in jeder anderen Konstellation der erklärenden Variablen signifikant sind. Das heisst zum Beispiel, dass in der ersten Regression mit den erklärenden Variablen Bruttoinlandsprodukt, Inflationsrate und Staatsverschuldung die Variablen Bruttoinlandsprodukt und Staatsverschuldung signifikant sind. In meiner zweiten Regression mit den erklärenden Variablen Bruttoinlandsprodukt, Inflationsrate,Staatsverschuldung und zusätzlich Pro-Kopf-Einkommen sind auf einmal die signifikanten Variablen nur noch das Bruttoinlandsprodukt und das Pro-Kopf-Einkommen. Kann dies sein?
Ist es also möglich dass ein erklärende Variable in der einen Regression signifikant ist und in einer anderen Regression mit anderen erklärenden Variablen nicht mehr?
Vielen vielen Dank an Alle, die bis hierhin gelesen haben und eine möglich Antwort auf eine der Fragen haben. Dies würde mir bei meiner Masterarbeit sehr helfen...
- lecoewf
- Beiträge: 7
- Registriert: Fr 25. Jan 2013, 19:02
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Ordered Probit/ Regression
![]() von aziz » So 3. Feb 2013, 16:11
von aziz » So 3. Feb 2013, 16:11
lecoewf hat geschrieben:Zu erst einmal jedoch zu deine Frage:Du benutzt nicht die origninalen Daten aus dem Paper?
Nein, ich benutze nicht die Originaldaten. Im ursprünglichen Paper wird die Untersuchung nur für die Ratingagentur Moody´s durchgeführt. Ich hingegen untersuche mögliche Variablen für die drei bekanntesten Ratingagenturen Moody´s, Standard & Poor´s und Fitch. Des Weiteren betrachte ich die Ratings von einer anderen Ländergruppe als im ursprünglichen Paper und zusätzlich nehme ich die Ratings aus einer anderen zeitliche Periode als im ursprünglichen Paper. Im Endeffekt "klaue" ich nur die Idee zu untersuchen, welche Faktoren eine Rolle für das Rating spielen.
Darauf wollte ich hinaus. Es sind völlig andere Daten (andere Länder und andere Periode). Deswegen würde ich mich diesbezüglich nicht über eine Diskrepanz zwschen den Ergebnissen des Papers und deinen Wunder.
Würdest du hingegen nur noch zusätzlich die Ratingergebnisse der anderen Agenturen hinzu nehmen und ansonsten die selben Länder zu den selben Perioden untersuchen, so würde mich dies eher stutzig machen, da sich die Ratings der verschiedenen Agenturen kaum unterscheiden sollten. Meines wissens basieren die Ratngs der verscheiden Agenturen auf hauptsächlich den gleichen Beurteilungskriterien. Ich denke, dass dies zwischen den Ratingagenturen nur leicht varieren wird.
lecoewf hat geschrieben:Wie gesagt, ich habe nur deinen Vorschlag die erklärenden Variablen als Kovariate einzusetzen umgesetzt und erhalte nun für jede Variablen einen einzelnen Regressionskoeffizient. Dies entspricht meinem Wunsch, wie die Ergebnisse dargestellt werden sollen. Was mich jedoch verwirrt ist, ob es wirklich Kovariate sind? Denn ich dachte immer, dass Kovariate eine Variable ist, von der vermutet wird oder bekannt ist, daß sie als Drittvariable den Zusammenhang zwischen anderen Variablen beeinflußt. Ist diese Definition meinerseits korrekt? Und stimmt dass denn für meine erklärenden Variablen?
Ich kenne dies nur unter dem Ausdruck Moderratorvariable. In SPSS bezeichnet eine Kovariate eine unabhängige Variable mit metrischen Salenniveau. So, wie ich es sehe trifft dies auf deine erklärenden Variablen zu. So hattest du es eingangs, glaub ich, beschrieben.
lecoewf hat geschrieben:Beim umsetzen des Vorschlags von aziz sind mir jedoch ein paar weitere kleine Fragen gekommen. Ich möchte mich schonmal für jede Antwort bedanken, da ich für jede Antwort/ Verweis/ Link oder ähnliches dankbar bin, denn mein SPSS-Buch lässt mich bei den folgenden Fragen leider im Stich
1. Frage: Welches ist das passende Pseudo R-Quadrat bei meiner Fragestellung (Cox und Snell, Nagelkerke oder McFadden)?
Dies sind im Grunde alle gleich "gut". Sie basieren nur auf unterschiedliche Berechnungsgrundlagen. Sie sollten alle ähnliche Werte liefern.
lecoewf hat geschrieben:2. Frage: In dem von mir nachgebauten Paper ist es so, dass es für jede Ordered Probit Regression einen Konstanten Term gibt. Wo steht der bei der Datenausgabe?
Ich habe nämlich herausgefungen, dass es zum Beispiel so ist, dass bei STATA dieser Wert nicht explizit ausgegeben wird. Ist dies auch bei SPSS so? Wie bekomme ich diesen Wert?
Du wirst bei der Modellierung irgendwo eine Option einstellen können mit der du ein Modell mit Achsenabschnitt anpassen kannst. Weiß aber auch nicht genau wo.
lecoewf hat geschrieben:3. Frage: Ich habe die erklärende Variable "Staatsausfall seit 1945". Diese Variable nimmt den Wert 1=Staatsausfall oder 0=kein Staatsausfall seit 1945. Es handelt sich also um eine Dummy-Variable bzw. nominale Variable. Meine Frage ist, wie ich diese Variable als möglichen Regressor in der Analyse einbaue. Tue ich dies als Faktor oder als Kovariate? Denn mein schlaues SPSS-Buch sagt, dass in dem Feld Kovariate nur intervallskalierte Variablen stehen dürfen. Wie füge ich nun also diese Variable ein?
Diese Variable musst du als Faktor modellieren. So wie du es ursprünglich mit sämtlichen Merkmalen getan hast.
lecoewf hat geschrieben:Letzte Frage: Da ich wie gesagt ein Paper "nachbaue" habe ich geguckt, wie die Ergebnisse des Papers sind um zu überprüfen, ob meine Werte in die richtige Richtung laufen. Beim "studieren" der Ergebnisse des Papers ist mir im Vergleich zu meinen Ergebnissen etwas aufgefallen was mich leicht irritiert. In dem Paper ist es so, dass erklärende Variable, die in einer ordered probit Regression einmal signifikant sind auch in jeder anderen Konstellation der erklärenden Variablen signifikant sind. Das heisst zum Beispiel, dass in der ersten Regression mit den erklärenden Variablen Bruttoinlandsprodukt, Inflationsrate und Staatsverschuldung die Variablen Bruttoinlandsprodukt und Staatsverschuldung signifikant sind. In meiner zweiten Regression mit den erklärenden Variablen Bruttoinlandsprodukt, Inflationsrate,Staatsverschuldung und zusätzlich Pro-Kopf-Einkommen sind auf einmal die signifikanten Variablen nur noch das Bruttoinlandsprodukt und das Pro-Kopf-Einkommen. Kann dies sein?
Ist es also möglich dass ein erklärende Variable in der einen Regression signifikant ist und in einer anderen Regression mit anderen erklärenden Variablen nicht mehr?
So etwas kann durchaus passieren. Das ist nicht ungewöhnlich. Nichtsdestotrotz wird dies seine Gründe haben. Das ist aber nur im Paper passiert, oder? Bei deinen Berechnungen nicht?
Gruß
Aziz
- aziz
- Beiträge: 34
- Registriert: Di 29. Jan 2013, 17:28
- Danke gegeben: 0
- Danke bekommen: 3 mal in 3 Posts
Re: Ordered Probit/ Regression
![]() von lecoewf » So 3. Feb 2013, 23:32
von lecoewf » So 3. Feb 2013, 23:32
Hallo aziz,
Ich habe es noch nicht für alle Ratingagenturen berechnet, aber bisher hast du Recht, dass die Ergebnisse nur leicht variieren.
Leider habe ich dies noch nicht gefunden. Falls du weitere Möglichkeiten/Ideen/Ansätze zur Lösung dieses Problem hast wäre ich sehr dankbar.
Was ich mich an dieser Stelle, jedoch gefragt habe ist:
Die ordered probit Gleichung ist ja eigentlich eine Gleichung folgender Form: Y = b*x+ Störterm. Diese Gleichung zeigt schon deutlich, dass es keinen konstanten Term/Achsenabschnitt gibt bzw. geben muss. Die Idee für einen Achsenabschnitt habe ich ausschließlich dem nachgebauten Paper entnommen, da er dort existiert.
Meine Frage, die sich daran anschließt ist: Welche Bedeutung/Interpretation hätte dieser konstanter Term überhaupt? Und inwiefern würde er mir bei der Berechnung helfen (außer, dass ich näher am ursprünglichen Paper bin)?
Bedarf es bei diesem Koeffizienten einer besonderen Interpretation oder ist dies analog wie bei den anderen Lage-Koeffizienten (resultierend aus intervallskalierten Variablen) möglich? Stellt dies also auch die Wahrscheinlichkeit dar?
Dieses "Problem" der sich ändernden Signifikanz bei unabhängigen Variablen bei verschiedenen Konstellationen tritt bei mir auf. So wie ich dich jedoch verstehe muss ich mir darum keine Gedanken machen und kann die Ergebnisse in meine Masterarbeit übernehmen.
Zum Abschluss habe ich noch eine "kleine" Frage .
.
Ich hoffe, dass du mir diese Frage vielleicht auch beantworten könntest, darüber wäre ich sehr dankbar.
Meine Frage bezieht sich auf die Modellannahmen beim ordered probit Model. Die einzige Annahme, die mir bekannt ist, ist die Annahme über die Parallelität der Linien.
Gibt es weitere Annahmen, die ich berücksichtigen muss?
Des Weiteren habe ich gelesen, dass diese Annahme bei intervallskalierten unabhängigen Variablen nicht umsetzbar ist? Dies würde zumindest mit meinen Ergebnissen übereinstimmen die keinerlei Signifikanz bei diesem Test aufzeigt. Ist dies korrekt?
Vielen vielen Dank nochmals für dein schnelles Antworten. Ich würde mich freuen, wenn du mir bei diesen und möglicherweise auch weiteren Fragen behilflich sein könntest.
PS: Natürlich bin ich auch jedem Anderen dankbar, der mir eine Frage beantwortet
Würdest du hingegen nur noch zusätzlich die Ratingergebnisse der anderen Agenturen hinzu nehmen und ansonsten die selben Länder zu den selben Perioden untersuchen, so würde mich dies eher stutzig machen, da sich die Ratings der verschiedenen Agenturen kaum unterscheiden sollten. Meines wissens basieren die Ratngs der verscheiden Agenturen auf hauptsächlich den gleichen Beurteilungskriterien. Ich denke, dass dies zwischen den Ratingagenturen nur leicht varieren wird.
Ich habe es noch nicht für alle Ratingagenturen berechnet, aber bisher hast du Recht, dass die Ergebnisse nur leicht variieren.
lecoewf hat geschrieben:
2. Frage: In dem von mir nachgebauten Paper ist es so, dass es für jede Ordered Probit Regression einen Konstanten Term gibt. Wo steht der bei der Datenausgabe?
Ich habe nämlich herausgefungen, dass es zum Beispiel so ist, dass bei STATA dieser Wert nicht explizit ausgegeben wird. Ist dies auch bei SPSS so? Wie bekomme ich diesen Wert?
Du wirst bei der Modellierung irgendwo eine Option einstellen können mit der du ein Modell mit Achsenabschnitt anpassen kannst. Weiß aber auch nicht genau wo.
Leider habe ich dies noch nicht gefunden. Falls du weitere Möglichkeiten/Ideen/Ansätze zur Lösung dieses Problem hast wäre ich sehr dankbar.
Was ich mich an dieser Stelle, jedoch gefragt habe ist:
Die ordered probit Gleichung ist ja eigentlich eine Gleichung folgender Form: Y = b*x+ Störterm. Diese Gleichung zeigt schon deutlich, dass es keinen konstanten Term/Achsenabschnitt gibt bzw. geben muss. Die Idee für einen Achsenabschnitt habe ich ausschließlich dem nachgebauten Paper entnommen, da er dort existiert.
Meine Frage, die sich daran anschließt ist: Welche Bedeutung/Interpretation hätte dieser konstanter Term überhaupt? Und inwiefern würde er mir bei der Berechnung helfen (außer, dass ich näher am ursprünglichen Paper bin)?
lecoewf hat geschrieben:
3. Frage: Ich habe die erklärende Variable "Staatsausfall seit 1945". Diese Variable nimmt den Wert 1=Staatsausfall oder 0=kein Staatsausfall seit 1945. Es handelt sich also um eine Dummy-Variable bzw. nominale Variable. Meine Frage ist, wie ich diese Variable als möglichen Regressor in der Analyse einbaue. Tue ich dies als Faktor oder als Kovariate? Denn mein schlaues SPSS-Buch sagt, dass in dem Feld Kovariate nur intervallskalierte Variablen stehen dürfen. Wie füge ich nun also diese Variable ein?
Diese Variable musst du als Faktor modellieren. So wie du es ursprünglich mit sämtlichen Merkmalen getan hast.
Bedarf es bei diesem Koeffizienten einer besonderen Interpretation oder ist dies analog wie bei den anderen Lage-Koeffizienten (resultierend aus intervallskalierten Variablen) möglich? Stellt dies also auch die Wahrscheinlichkeit dar?
lecoewf hat geschrieben:
Letzte Frage: Da ich wie gesagt ein Paper "nachbaue" habe ich geguckt, wie die Ergebnisse des Papers sind um zu überprüfen, ob meine Werte in die richtige Richtung laufen. Beim "studieren" der Ergebnisse des Papers ist mir im Vergleich zu meinen Ergebnissen etwas aufgefallen was mich leicht irritiert. In dem Paper ist es so, dass erklärende Variable, die in einer ordered probit Regression einmal signifikant sind auch in jeder anderen Konstellation der erklärenden Variablen signifikant sind. Das heisst zum Beispiel, dass in der ersten Regression mit den erklärenden Variablen Bruttoinlandsprodukt, Inflationsrate und Staatsverschuldung die Variablen Bruttoinlandsprodukt und Staatsverschuldung signifikant sind. In meiner zweiten Regression mit den erklärenden Variablen Bruttoinlandsprodukt, Inflationsrate,Staatsverschuldung und zusätzlich Pro-Kopf-Einkommen sind auf einmal die signifikanten Variablen nur noch das Bruttoinlandsprodukt und das Pro-Kopf-Einkommen. Kann dies sein?
Ist es also möglich dass ein erklärende Variable in der einen Regression signifikant ist und in einer anderen Regression mit anderen erklärenden Variablen nicht mehr?
So etwas kann durchaus passieren. Das ist nicht ungewöhnlich. Nichtsdestotrotz wird dies seine Gründe haben. Das ist aber nur im Paper passiert, oder? Bei deinen Berechnungen nicht?
Dieses "Problem" der sich ändernden Signifikanz bei unabhängigen Variablen bei verschiedenen Konstellationen tritt bei mir auf. So wie ich dich jedoch verstehe muss ich mir darum keine Gedanken machen und kann die Ergebnisse in meine Masterarbeit übernehmen.
Zum Abschluss habe ich noch eine "kleine" Frage
Ich hoffe, dass du mir diese Frage vielleicht auch beantworten könntest, darüber wäre ich sehr dankbar.
Meine Frage bezieht sich auf die Modellannahmen beim ordered probit Model. Die einzige Annahme, die mir bekannt ist, ist die Annahme über die Parallelität der Linien.
Gibt es weitere Annahmen, die ich berücksichtigen muss?
Des Weiteren habe ich gelesen, dass diese Annahme bei intervallskalierten unabhängigen Variablen nicht umsetzbar ist? Dies würde zumindest mit meinen Ergebnissen übereinstimmen die keinerlei Signifikanz bei diesem Test aufzeigt. Ist dies korrekt?
Vielen vielen Dank nochmals für dein schnelles Antworten. Ich würde mich freuen, wenn du mir bei diesen und möglicherweise auch weiteren Fragen behilflich sein könntest.
PS: Natürlich bin ich auch jedem Anderen dankbar, der mir eine Frage beantwortet
- lecoewf
- Beiträge: 7
- Registriert: Fr 25. Jan 2013, 19:02
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
5 Beiträge
• Seite 1 von 1
Wer ist online?
Mitglieder in diesem Forum: 0 Mitglieder und 3 Gäste